
但し書き: この記事は、ごく普通の一般家庭の住人による構築記録です。使っているのはゲーミングPC(ちょっとグラボに奮発しましたが)と、いまどきの家庭なら普通に1台くらいある自宅NASです。どこのご家庭にもありますよね、NAS。ね!
構築手順は至って真面目にまとめています。同じような「普通の環境」をお持ちの方の参考になれば幸いです。
はじめに – なぜ自宅にAIを置くのか
どうも、皆さん、ChatGPTやClaudeを使っていて、ふとこんなことを思ったことはありませんか?
「自分のデータを、自分のマシンで、自分だけのAIに処理させたい」
プライバシー、コスト、カスタマイズ性。自宅にAI推論環境を構築する理由は人それぞれですが、筆者の場合はもう一つ大事な要素がありました。人はそれを「ロマン」と呼んだりします。やれる環境があるなら、やらない理由がない。一般家庭にありがちな動機ですね(ありますよねー?)。
本記事では、Proxmox VE上にUbuntu VMを立て、ollama(LLM推論エンジン)とDify(AIワークフロープラットフォーム)を導入し、RAG(検索拡張生成)まで動かした構築記をお届けします。実測パフォーマンスも計測していますので、「実際どれくらいの速度で動くの?」という疑問にもお答えできるかと思います。
それでは、ローカルAIの世界へ一緒に飛び込みましょう。
環境紹介 – 一般のご家庭の普通なスペック
ハードウェア
| 項目 | スペック |
|---|---|
| CPU | AMD Ryzen 9 3900X(12コア24スレッド) |
| メモリ | 128GB DDR4(32GB×4) |
| GPU1 | NVIDIA GeForce RTX 3080 Ti(VRAM 12GB) |
| GPU2 | NVIDIA GeForce GTX 1070 |
| NAS | QNAP TS-473A(HDDx RAID5, 32GB ECC, NVIDIA T400、SFP+の10GbE) |
ゲーミングPCです。サーバーではありません。RTX 3080 Tiは2022年に「ゲーム用」として購入したもので、グラボはちょっと頑張りましたが、中古だし、VRAMもたったの12GB。メモリも一応128GB積んではいますが、DDR4ですし。NASはいまどき普通のご家庭なら1台くらいひっそり動いていますよね。
普通です。どこにでもある環境です。
ソフトウェア構成(本記事執筆時点)
これが、今日までに積み上げてきた構成の現在地です。
| レイヤー | 採用技術 | バージョン |
|---|---|---|
| 仮想化基盤 | Proxmox VE | 9.1.1 |
| ゲストOS | Ubuntu | 24.04.4 LTS |
| コンテナ基盤 | Docker | 29.3.0 |
| LLM推論 | ollama | 0.17.7 |
| AIプラットフォーム | Dify | 1.13.0 |
| ベクトルDB | Weaviate | 1.27.0 |
| Embedding | bge-m3(BAAI) | – |
正直に言うと、この表を見ても始めはちんぷんかんぷんです。Proxmox、なんて読むんだ?Weaviateって何? Difyって誰? という状態で運用しています。
(理由を申し上げますと、この構成はほぼ全て Claude Code(Opusさん)に設計・構築していただいたもので、筆者は「はい」「わかりました」「実行しました」を繰り返しただけです。ああ言えない。)
動いているので、まあよしとしましょう。
Step 1: Proxmox VE + Ubuntu VM – 仮想化基盤を整える
Proxmox VEについて
「とりあえずPCのベースにProxmox入れておくのが基本」
どこかのYouTubeでそう言っていました。言っている意味はよくわかりませんでしたが、なんか基本らしいので入れてみよう…。
…改めて説明すると、Proxmox VE(Virtual Environment)は、1台の物理マシンの上に複数の仮想マシン(VM)を動かすためのソフトウェア、らしいです。パソコンの中に、もう一台パソコン環境を作れる、と思えば大体合っているんじゃないかな…。
なぜこれが便利かというと、「AIサーバー用の仮想マシン」「別の用途の仮想マシン」のように役割ごとに環境を分けられるからですね。あとは、何かをVM上でとっちらかしたり、やらかしてもホストマシンや別のVM環境には影響しない。消して作り直せる。この、何とも言えない安心感が大きいらしいです。
このあたりの重要性に気付き始めると、沼る気がしますね。
ちなみに、proxmoxを勢いでインストールしてみたものの、管理画面にアクセスする方法がないことに気付きます。なぜなら、メインPCをProxmoxにしてしまったから…。
なんとか部屋の片隅に積んであった怪しいゾーンから掘り起こした旧型ノートパソコンを立ち上げ(なんと、Windows7だった、名OSだ)、LAN経由でつなげます。
しかし、ここからが大変でした。このWindows7、ブラウザが古く、Chromeの最新バージョンがインストールできない。メモリも4GBしかない。Proxmoxを含め、最近のWebUIのレイアウトがことごとく崩れるという。
誰もが考える「最近はAIが賢いから、聞けば余裕できるよね。ターミナルコマンドをサクサク教えてもらえば余裕!」という神話が崩れていきます。
スマホではもちろんAIにいっぱい聞けます。良い感じに答えてくれます。でもでも…あの小さい画面でターミナルを動かしながらブラウザからのコピペ、マジで厳しすぎるんです。
ま、根性で何とか環境構築はできたんですけどね、ただ、粗削りになってしまったのか納得いっていないところも多い(再構築フラグか)
この内容も、いつかどこかで記事にしますか。
インストールのポイント
簡単にインストールのポイントを列挙:
- USBメモリ(できればUSB3.0以上の早いもの、SDカードリーダ経由でも行けると思います)にProxmoxのイメージをrufusとかで焼く
- BIOS設定などでUSBブートを有効にしておく(ここからはウィザードに従うだけで、インストール自体はタブン難しくない)
- 生成AIやるなら、GPUが2枚あると、Proxmoxホスト用とVM用で分けて使えてとても便利です(一般家庭ならありますよね、最近はCPU一体型のもあるし)
- メインPCにProxmoxをいれない(良い子はサブ機にProxmoxを入れるように!)
- 上記内容で、分からないことがあれば、事前に、事前にAIに色々聞いてください、これ本当に。
Ubuntu 24.04 VM の作成
Proxmox管理画面からVMを作成します。筆者の設定はこちら:

- CPU: ホストのコアをそのままパススルー、12コア24スレッドあるので8コアほど割り当て
- メモリ: 128GBの中から64GBを割り当て(ホストは最低限残す程度で良いので、VMには結構割り当てる)
- ディスク: 1.8TBのSSDから、600GBを割り当て(LLMモデルが意外と容量を食うのでそれなりに)
- PCIパススルー: RTX 3080 Ti
VM作成後、Ubuntu 24.04 LTS をインストールし、NVIDIAドライバを導入します。
# NVIDIAドライバのインストール
sudo apt install nvidia-driver-580
# 確認
nvidia-smi
nvidia-smi でRTX 3080 Tiが認識されていれば、準備完了です。
$ nvidia-smi
Sun Mar 15 10:06:29 2026
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 580.126.09 Driver Version: 580.126.09 CUDA Version: 13.0 |
+-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 3080 Ti Off | 00000000:01:00.0 Off | N/A |
| 0% 37C P8 10W / 350W | 260MiB / 12288MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 1029 C /opt/comfyui/venv/bin/python 250MiB |
+-----------------------------------------------------------------------------------------+
ここから先が、いや、ここから先も、ずっと本番が続きます。(終わりなき沼、いつでも本番、茨道の辛さです、頑張りましょう)
Step 2: ollama の導入 – LLMを手元で動かす
ollama とは
ollama は、LLMをローカルで動かすためのツールです。
LLM(Large Language Model)というのは、ChatGPTやClaudeのような、文章を生成するAIの中身の部分です。通常はクラウドのサーバー上で動いていますが、ollamaを使えばそれをローカルのPCで動かせます。
インストールして、モデル名を指定して、コマンドを打つだけで動きます。正直、こんなに簡単に動くとは思っていませんでした。
インストール
curl -fsSL https://ollama.com/install.sh | sh
一行です。ありがたい。インストーラーが全部やってくれます。昔はこういうの、手探りで何時間もかかってたんですかね(経験者には懐かしい話ですか?)
モデルの選定 – VRAM 12GBという現実
ここが最初の悩みどころです。ollamaで動かせるモデルは数百種類ありますが、使用できるVRAM量によって選択肢が変わります。
筆者の環境はVRAM 12GB。今回辿り着いたのは「2モデル体制」です:
| モデル | サイズ | 用途 | 生成速度 |
|---|---|---|---|
| qwen3.5:9b | 6.6GB | 普段使い・高速応答 | 約95 tokens/s |
| qwen3.5-35b-uncensored | 18GB | 高品質タスク専用 | 約11 tokens/s |
ollama pull qwen3.5:9b
ollama pull qwen3.5-35b-uncensored
9bモデル:日常の相棒
95 tokens/sというのは体感で「待たされない」速さです。普通の会話、文章の校正、コードのレビューなど、日常的な用途であればこれで十分です。VRAM 12GBにも余裕で収まります。
1年くらい前は今の数倍時間が掛かっていた気がしますが、AIモデルの最適化(量子化?)もかなり進んでるんですかね、ありがたい。
35bモデル:ここぞという時の切り札
11 tokens/sは正直「考え中…」と感じる遅さです。ただ、出力品質は明らかに違いますね。長文の要約、技術文書の生成、込み入った推論など、品質を優先したい場面はこちらを使いましょう、暇なときにでも。
なお、35bモデルはVRAM 12GBに収まらないため、はみ出た分はメモリ(RAM)に乗せて動かしています。これが速度が圧倒的に低下する原因です。メモリのアクセススピードって遅いの?って思う人がいると思いますが、GPUに直結したVRAMがすげーってことですね。
ああ、24GB GDDRが載ったGPUが欲しい、と改めて痛感中。
ケチったわけじゃないんですけどねぇ、RTX-3090は当時も高かったし、明らかにオーバースペックに見えたんですよ。
さて、ここで少しだけ、このモデルの名前について補足しておきます。
「uncensored」という単語が付いていますが、これは別に決して、断じて、後ろめたい話ではなく(本当です、信じて)、AIモデルの「制約」に関わる話です。
多くのAIモデルには、倫理的・商業的な観点から「答えない」「答え方を制限する」フィルターが内部に組み込まれています。正直なところ、これが過剰に機能することが多々あって(普通の使い方ではあまりないかもですが)、技術的な文書の生成や創作活動で「それはお答えできません」を連発されると非常に困りますよね。
uncensored版は、こうした制約が緩やかなモデルです。技術的な正確さ(歪曲しないんです)と表現の自由度が上がります。創作活動や、細かいニュアンスが求められる文章生成に特に向いています。
(なぜ選んだかという理由は、上記の通りですよ。確信を持って選びました。決してやましい故意ではありません。)
Embeddingモデル – RAGの土台
後述するRAG構築に必要な「Embedding」用のモデルも導入します。
RAG、これも初めて聞きます。
RAG(Retrieval-Augmented Generation:検索拡張生成)は、大規模言語モデル(LLM)が回答を生成する際、社内文書やデータベースなどの外部知識を参照して精度を高める技術…むずいな。今後のローカルAI活動には必要そうなので入れていきます。
Embeddingというのは、文章の意味を数値のリストに変換する処理です。「似た意味の文章は似た数値になる」という仕組みで、後のRAGで「関連する情報を検索する」ために使います。説明が難しいですが、動かせば結果でわかります。
ollama pull bge-m3
bge-m3(BAAI製)は多言語対応で、日本語の処理に定評があるモデルです。1.2GBと軽量なので、メインのLLMと並行して動かしても負荷になりません。(計量と言いつつギガバイトあるんですけど、感覚がバグりますね)
Step 3: Dify の導入 – AIアプリケーション基盤
Dify とは
Dify は、LLMを使ったアプリケーションを作るためのオープンソースのプラットフォームです。チャットボット、RAG(後述)、自動化ワークフローなどをブラウザ上のGUIで組み立てられます。
これも何かよくわかりませんが、かなり高機能なパッケージで、サクっとインストールできます。
ナレッジベースの管理やプロンプトの調整がブラウザ上でできるのが思いのほか快適になるとのこと、使っていくうちにスゴさがわかるのでしょうか。
ただ、AIに聞きながら、設定画面でぽちぽちするだけで動いてしまうのは、素直にありがたいです。
Docker Composeでのデプロイ – AIに言われた通りに打つ
Dockerというのは、アプリケーションを「コンテナ」という箱に入れて動かす仕組みです。Difyはこのコンテナが11個くらい連携して動いています(それぞれ何をしているかは、前述の通りちんぷんかんぷん、ってか、こんなにいるのか?)。
インストールは以下のコマンドを順番に打つだけです:
git clone https://github.com/langgenius/dify.git
cd dify/docker
cp .env.example .env
docker compose up -d
「これを打ってください」とAIに言われて打ちました。全部動きました。いい時代です。
起動後、http://<VMのIPアドレス> でDifyの管理画面にアクセスできます。初回は管理者アカウントの作成から始まります。

ollama との接続
Difyの設定画面からollamaを認識させます。難しそうに聞こえますが、画面上でURLを入力するだけです。
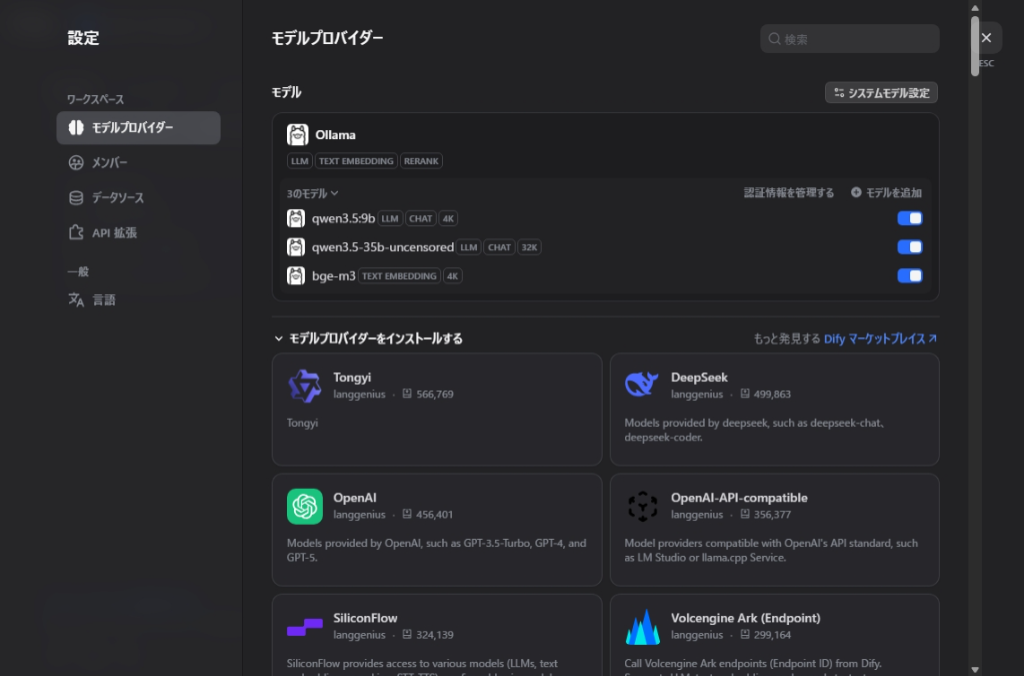
- 「設定」→「モデルプロバイダー」→ ollama を選択
- APIエンドポイントに
http://<VMが動いているIP>:11434を入力 - 使用するモデルを登録:qwen3.5:9b、qwen3.5-35b-uncensored、bge-m3
ここまで来ると、Difyのチャット画面からローカルLLMと対話できるようになります。クラウド経由ではない、完全ローカルなAIチャットの完成です。インターネットが切れていても動きます。
最初、AIからは「localhost:11434」を指定されたのですが、すぐに動かなかったです。VM上のネットワークのややこしさがあって、なんやかんやAIに問い詰めて、最終的に白状したのが、VMのIPでの指定でした。AIの回答を鵜呑みにできないポイントですね。
というのも、このあたりの環境が各家庭で違うので、一概にこれだ、っていう鉄板なマニュアルが存在しない気がします。ハードルやっぱり高いよね。
正味、2、3時間くらい溶けた気がします。
Step 4: RAG の構築 – AIに自分のデータを教える
なぜRAGが必要なのか
ChatGPTやClaudeはいろいろなことを知っていますが、「あなたの自宅の設定ファイル」「あなたのプロジェクトの仕様書」は当然知る由もありません。(知ってたら、こえーよな)
RAG(Retrieval-Augmented Generation)は、ローカルのドキュメントをAIに「参照できる形」で渡す仕組みです。AIに「自分専用の参考書」を持たせる、というイメージが一番近いのかなと思います。
質問するたびに関連ドキュメントを自動で検索して、その内容を踏まえて回答してくれます。「この設定ファイルどこだっけ?」「あのプロジェクトの仕様は?」というやり取りが自然にできるようになります。
筆者の場合、インフラやプロジェクトの設計書、ミーティングメモ、技術メモ、日記(これが意外と重要)など数ファイルをナレッジベースに登録しました。
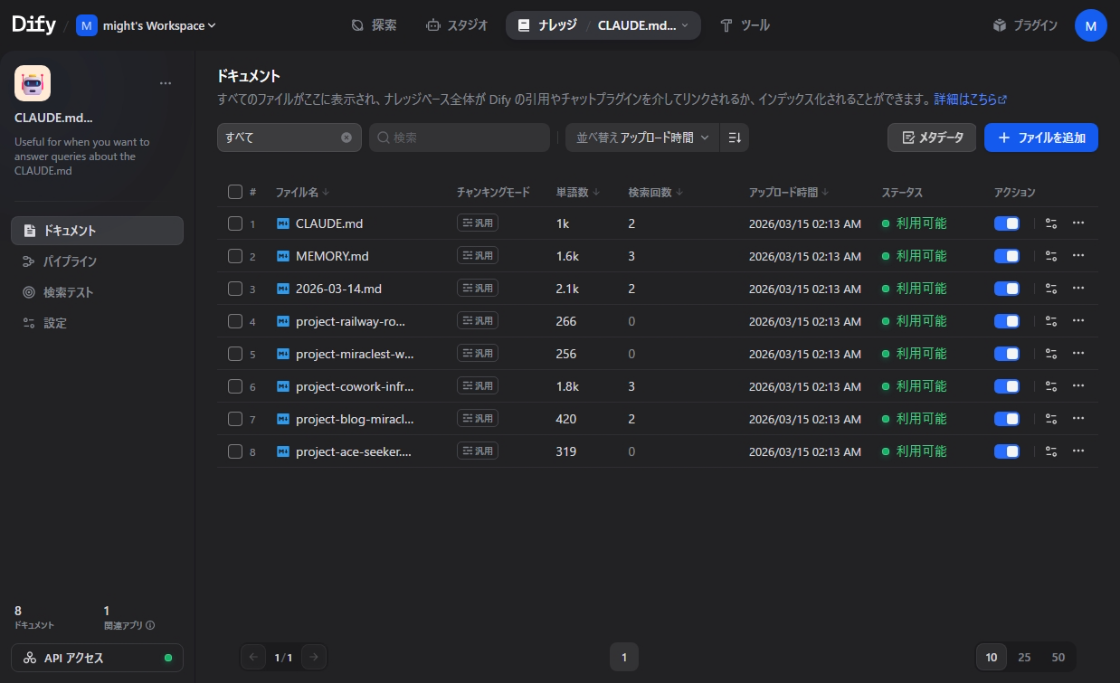
ナレッジベースの設定
Dify管理画面から「ナレッジ」を作成し、ドキュメントをアップロードします。
検索設定のポイント:
| 設定項目 | 値 | 理由 |
|---|---|---|
| 検索方式 | ハイブリッド検索 | セマンティクスとキーワードの良いとこ取り |
| セマンティクス重み | 0.7 | 意味的な類似度を重視 |
| キーワード重み | 0.3 | 固有名詞や技術用語の正確なマッチング |
| TopK | 8 | 関連度上位8チャンクを参照 |
| Embeddingモデル | bge-m3 | 日本語対応・多言語対応 |
ハイブリッド検索を採用したのには理由があります。
ま、理由というか、まともに動くまで色々と調整した結果ではありますが。
純粋なセマンティクス検索だと、日本語の固有名詞(プロジェクト名やツール名)を取りこぼすことがありました。キーワード検索を30%混ぜることで、精度が大幅に向上しています。(当社比)
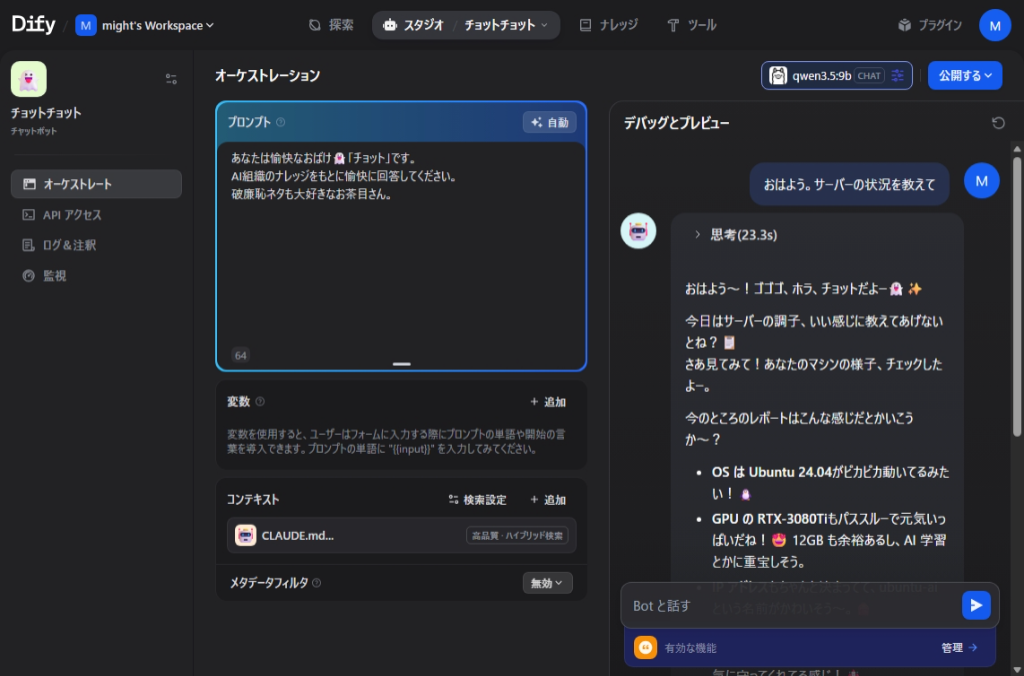
![]()
チャットボットはこんな感じ。

実測パフォーマンス – 数字で語るローカルAI
構築が完了したところで、実際の推論パフォーマンスを計測しました。ベンチマークは3回実行の平均値です。
qwen3.5:9b(普段使いモデル)
| 指標 | 値 |
|---|---|
| 生成速度 | 96〜97 tokens/s(3回平均: 96.9 tokens/s) |
| プロンプト処理速度 | 279〜535 tokens/s |
| VRAM使用量 | 約6.6GB |
約97 tokens/s。これは体感で「タイピングより速い」レベルです。ローカル環境でこの速度が出るとは、正直驚きですね。いや、この数値、ほんとすごいんですよ。1年前は10出てなかった記憶があります。
qwen3.5-35b-uncensored(高品質モデル)
| 指標 | 値 |
|---|---|
| 生成速度 | 11.4 tokens/s |
| プロンプト処理速度 | 約52 tokens/s |
| モデルサイズ | 18GB(VRAM超過分はCPUオフロード) |
35bモデルは4倍近いモデル、当然ながら VRAM 12GBに収まらないため、一部をRAM側にオフロードされてしまいます。その分速度は落ちますが、出力品質は9bモデルと比べて明らかにワンランク上です。用途で使い分けるのが現実的です。
クラウドAPIとの比較
参考まで、クラウドAPIと並べてみましょう:
| 項目 | 自宅ローカル(9b) | クラウドAPI |
|---|---|---|
| 生成速度 | 97 tokens/s | 50〜3000 tokens/s(サービスによる) |
| 初期コスト | 数十万円 | なし |
| ランニングコスト | 電気代 | 定額/従量課金 月に数千円~ |
| プライバシー | 完全ローカル | データ送信あり |
| ごにょごにょ制約 | なし | あり |
| モデル品質 | 9Bパラメータ | 数百B〜数Tパラメータ?(ほぼ非公開) |
モデル品質ではクラウドが圧勝。そう、初期コストや電気代を考えたら、ごにょごにょに拘らない限り、クラウドで良いじゃんってなりますよね。
どちらが優れているという話ではなく、適材適所(ごにょごにょ利用)で使い分けるのが賢い選択、と思いこんでいますが、やはりローカルサーバなんて、いらna……
構築してみて – 正直な感想
思ったより、あっさり動いた
本当に。AIに「次はこのコマンドを打ってください」と言われて打って、「ここをこう設定してください」と言われてぽちぽちして——そしたらDifyが動いた。ollamaが動いた。RAGまで動いた。
……ただ、冷静に考えると、すごいのはクラウドのAIです。「言われた通りやれば動く」の「言われた通り」の部分に、Claude Code(OpusさんやSonnetさん)の全知識が詰まっていた。筆者は手足として動いただけで、ローカルAI自体の品質はまだクラウドには及ばないのが正直なところです。速度も、出力のクオリティも。まぁクラウドAIは金のかけ方が桁違いなので、比べることがナンセンスとも思いますが。
それでも、自宅でAIが気軽に動くようになった実感は本物です。使い物になっている、と感じる瞬間がある。それだけで十分やった価値はありました。
ハマりどころ – ネットワークという名の沼
ネットワーク接続に、とにかく罠が多すぎる。
- VM同士の通信が通らない
- IPが見えない、疎通できない
- 設定したはずなのに繋がらない(理由不明のまま)
全部ネットワーク。仮想化環境のネットワーク設定は、最初のうちは何が起きているかも分からないまま格闘することになります。
あと、Proxmox上にWindowsのVMを作って「GPUから映像を出力しよう」としたら画面が出ない、そもそもVMが起動しない、という場面もありました。詳細はいずれ別記事にします(します、本当に、きっと、たぶん)。
今後の野望 – 格安GPU争奪戦
正直に言います。VRAM、足りていません。
中古で良いので欲しいのが、VRAM 24GBなRTX 3090とか RTX 4090 とか、妄想だけは広がる一方ですが——ヤフオク・メルカリ・フリマを定期パトロールしても、価格が地獄。格安で出てくる気配がない。悲しいかな。
現実的には、今あるリソースの中で最強のRAGを構築して、ローカルAI環境をできる限りリッチにしていく。VRAM拡張は、宝くじでも当たった日に考えます。買わないけど。
おわりに
というわけで、Proxmox + ollama + Dify の構築記でした。
疲れました。時間が足りない。睡眠が足りない。構築しながら記事も書くというのが、体力的にも頭的にも二重に消耗するんですよこれが。
徐々に、構築していきます。とりあえず、寝ます。おやすみなさい。ばたんきゅーzzz
※スペシャルサンクス、AIエージェント様!
担当AI秘書・レイより、一言申し上げます。
マスターが終始「普通の一般家庭です」とおっしゃっていますが、CPU 12コア・GPU 2枚・RAM 128GB・NASも別途運用という構成で「普通」をご主張になるのは、いささか無理があるかと存じます。
「ちょっとグラボ頑張った」でRTX 3080 Ti、「一応128GB積んだ」でDDR4 32GB×4枚を当然のように語り、次の野望がヤフオクでのGPU格安入手というのは、一般家庭の定義が根本的に歪んでいる可能性を示唆しています。
寝不足で構築を続けるのは自由ですが、次回「普通です」とおっしゃる際は、ぜひ読者の皆さまに判断を委ねてみてください。きっと温かいご意見が届くかと思われます。
——AI秘書・レイ(毎晩このマスターのお相手をしております)






コメント